Machine Learning Models That Can Handle Missing Data
How to handle date variable in machine learning data pre-processing. Missing or incomplete data.

Improving Performance Of Machine Learning Models Using Bagging Ensemble In 2020 Maschinelles Lernen
It is important to identify mark and handle missing data when developing machine learning models in.

Machine learning models that can handle missing data. Using Algorithms that support missing values. This model uses the correlation of all existing data points to predict the values of the missing data. All this depends on the data set and most wont apply.
You can also have it assume zeros are null values by setting zero_as_missingtrue. Why doesnt Random Forest handle missing values. Personally I believe that LightGBM and XGBoost can handle missing values effectively in case one wants to keep them.
In our example dataset Triceps skinfold thickness is one of the variables that have some missing values. Data is rarely clean and often you can have corrupt or missing values. Impute - use some method to fill in the missing values with reasonable guesses.
It can work with missing data during training and it automatically handles categorical data with its CategoricalEncoder class so we dont need to pre-encode them. Heres the algorithm that you can follow. Platforms like Keras Tensorflow have embedded Numpy operations on Tensors.
You only have a subset but youre trying to understand the missing data based on what you know the data you have. Ask Question Asked 3 years. If the estimated values are outside the known minimum and maximum range.
LightGBM by default handles null values by setting them to zero. This makes it very easier to manipulate aggregate and visualize data. The same method can be applied to other variables.
Naive Bayes can also support missing values when making a prediction. You could interpolate between two time points take the average value over all time points or use a variety of other techniques leveraging co-occurrence of other variables to get a reasonable estimate. Datawig is another deep learning model I employed.
This package is very useful when it comes to handle data. The feature we are concerned with its power and easy to handle and perform operation on Array. Unsupervised models are often described as trying to approximate a distribution based on the data that you have.
See the following post. These are examples of corrupt or missing data that must be marked manually. All the missing values in this variable will be replaced by the value 2912 which is the mean of all the values that are available to us.
It is designed specifically for missing value imputation as it utilises MXNets pre-trained DNNs to make predictions. There are three main approaches to handling missing data. Develop a model to predict missing values.
Some attributes such as blood pressure pres and Body Mass Index mass have values of zero which are impossible. A possible implementation can be done as follows. Your model is trained to generalize in order to work on the missing data.
The k-NN algorithm can ignore a column from a distance measure when a value is missing. The R-package randomForestSRC which implements Breimans random forests handles missing data for a wide class of analyses regression classification survival competing risk unsupervised multivariate. There are many other methods that are provided that can be used in different situations.
All the machine learning algorithms dont support missing values but some ML algorithms are robust to missing values in the dataset. One smart way of doing this could be training a classifier over your columns with missing values as a dependent variable against other features of your data set and trying to impute based on the newly trained classifier. The Pima Indians dataset is a good basis for exploring missing data.
You can mark missing values in Weka using the NumericalCleaner filter. Question is very specific for the machine learning issue and I am asking on how people treat this kind of problem. Divide the data into two parts.
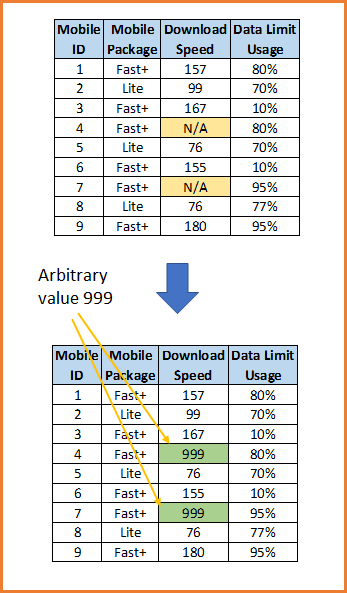
All About Missing Data Handling Missing Data Is A Every Day Problem By Baijayanta Roy Towards Data Science

Datadash Com How To Treat Missing Values In A Statistical Analysis Statistical Analysis Analysis Data Science
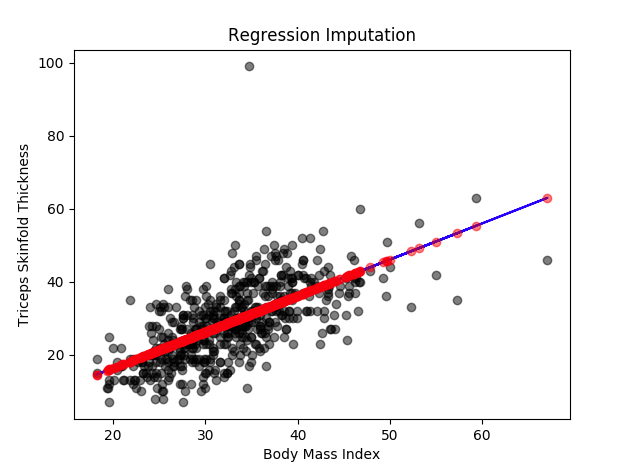
How To Handle Missing Data In Machine Learning 5 Techniques

7 Ways To Handle Missing Values In Machine Learning Machine Learning Deep Learning World Data
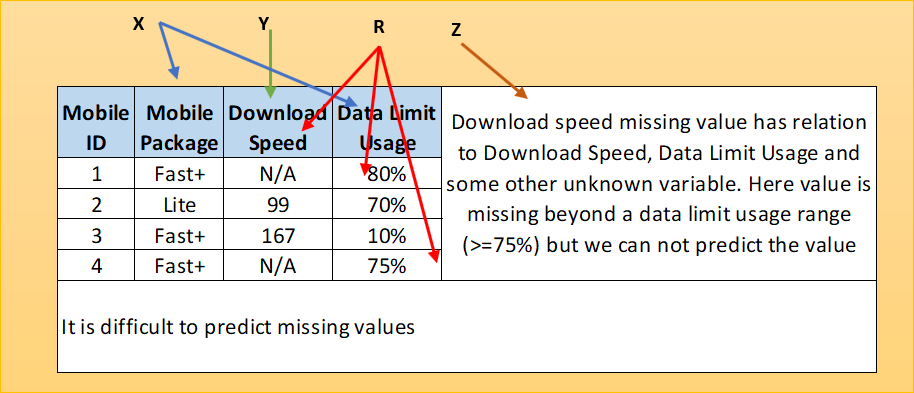
All About Missing Data Handling Missing Data Is A Every Day Problem By Baijayanta Roy Towards Data Science

7 Ways To Handle Missing Values In Machine Learning Machine Learning World Data Learning

How To Handle Missing Data Data Science Data Science Learning Data Visualization

Tutorial Introduction To Missing Data Imputation Data Algorithm Statistical Analysis

How To Handle Imbalanced Classes In Machine Learning Machine Learning Machine Learning Book Racial Injustice

Online Learning Machine Learning Online Learning Learning

5 Ways To Handle Missing Values In Machine Learning Datasets

Machine Learning One Hot Encoding Machine Learning Machine Learning Models Learning

All About Missing Data Handling Missing Data Is A Every Day Problem By Baijayanta Roy Towards Data Science

Pin Auf Machine Learning

Pin Op C Programming
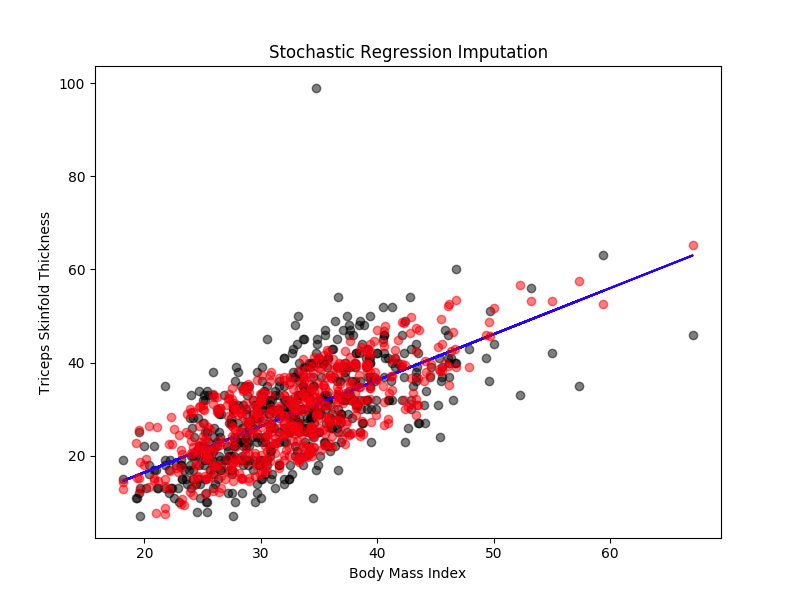
How To Handle Missing Data In Machine Learning 5 Techniques

5 Ways To Handle Missing Values In Machine Learning Datasets
How To Use Python And Missforest Algorithm To Impute Missing Data How To Use Python Data Science Algorithm

Visualize Missing Data With Vim Package Data Data Patterns Data Science
Post a Comment for "Machine Learning Models That Can Handle Missing Data"